
SimFlood: from open data to open models
The first open data hack event I ever attended was in Leeds in March 2014, run by Leeds Data Mill. It was just a few months after widespread flooding in Somerset and The Environment Agency sent some of their top people. They helped us sign up for access to their opendata portal and took notes on what we liked and what we didn’t.
I learned a lot from Simon and Harriet that weekend. I learned how to work with shapefiles so that we could draw flood risk areas on a map. I learned new ways to geo-locate properties so that we could plot every planning permission in Leeds on the same map. Together we learned that in West Yorkshire councils almost never grant planning permission on flood plains.
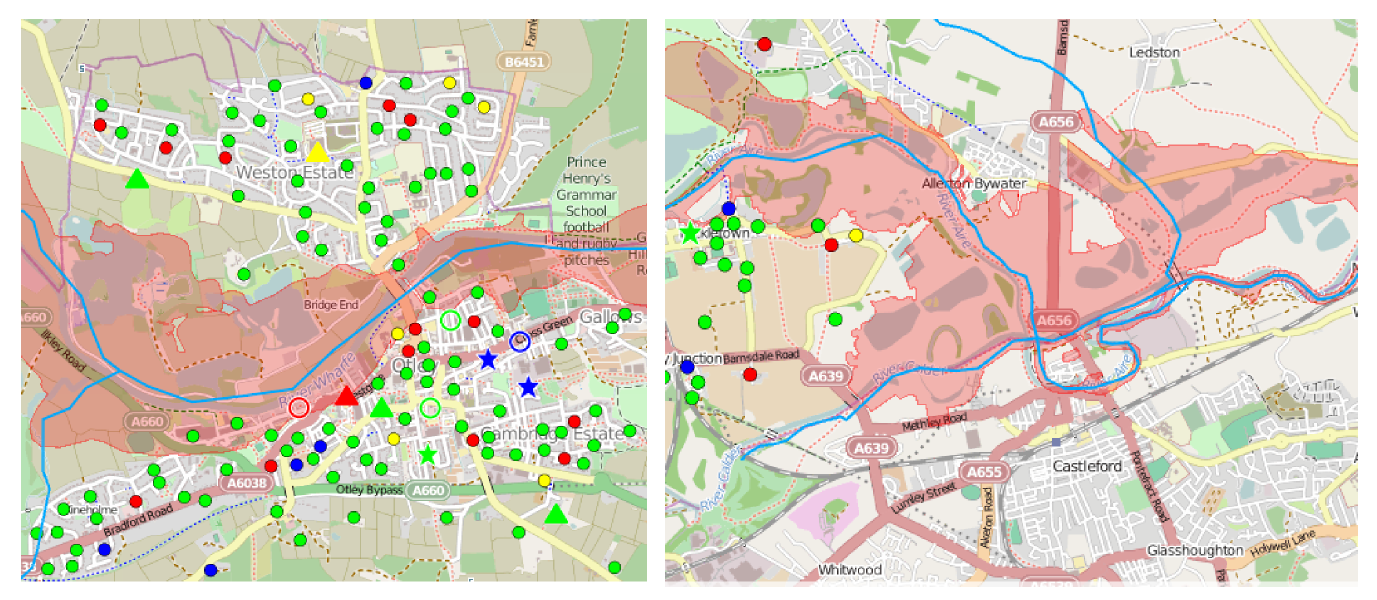
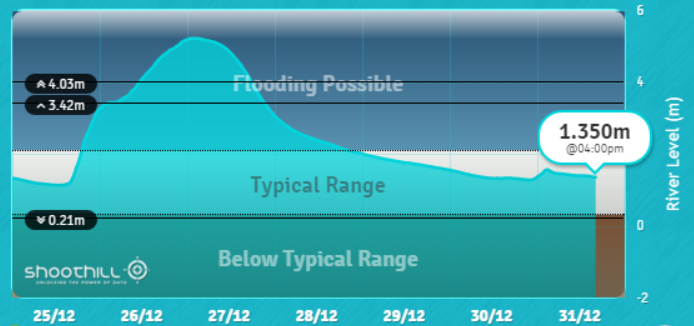
Twenty months later, flooding hit Leeds. I was at my Dad’s in Wharfedale for Christmas and for a while completely cut off from the rest of Yorkshire. The media focused on the worst-affected areas of Leeds and our offices weren’t among them. Yet I could monitor the flooding in real-time thanks to fantastic open innovations by Jeni Tennison, Shoothill, and many more. I didn’t need to travel to save my equipment because I could tell that only our basement would be flooded.
In the next twenty months we’ll see even bigger advances in our power to monitor flooding. Cheap river level sensors that run for years on a single charge are being developed by flood network in Oxford. The UK’s first free and open LoRaWAN network to allow them to deliver readings in real-time has been deployed by Things Manchester.
We’ll soon have open Lidar data for the whole of the UK so that we can understand the catchment area of every river. In the coming year, we’ll see tools that make that data accessible to everyone.
So what next?
In early 2016 I’ll be working at ODILeeds and with others to organise a FloodHack in the North of England. We’ll discuss what we should do next and then do it. You will all be invited.
Until then here’s something to get you thinking.

Two years ago the environment agency knew a lot about flooding. The public knew very little. Today the public has access to a huge amount of data and great tools to understand it.
Today government agencies have a good understanding of what affects flooding. We can’t stop the rain but we can do a lot to defend ourselves from floods or design our environment so that flooding is reduced. The problem is that the models we need to answer questions like “how many properties in Hebden Bridge were flooded as a result of burning moorland?” aren’t open. Communities can achieve something with protests but they will achieve more if they can offer, and price, alternatives.
When it comes to open models, we’re where we were with open data two years ago. If we want to make a truly democratic decision on how we manage our rivers, how we use our land, and where we invest our money in flood defences we need to fix that. We need to understand the impact of our choices, let people play with different choices, and then build data-led arguments based on that process.
In 2016 I’ll be building SimFlood. I’ll be building the tool that George Monbiot can use to quantify the cost of burning moorland and straightening rivers. It will be scientifically rigorous but as easy to understand as a video game. I’m already looking for people to help build it, shape it, and support it.
Can you?