Building The Data City
, .
When I stopped being paid to do science I realised that my productivity was lower without keeping a lab book. So I started writing a blog in 2013. It’s like a lab book, but better, since other people can respond.
Since then I’ve averaged one blog post per week. In 2019 I managed one per month. My rate for 2020 is not much higher. This post explains why. It contains lots of simplifications and lots of links to more details. It also reads like a sales pitch. Because it is.
Building The Data City
Me and co-founders Paul and Alex have been building The Data City for about seven years, often without realising it. In 2016 and 2017 projects like the UK Tech Innovation Index had helped us match up our technology with the UK government’s emerging interest in industrial strategy. We were reminded that no-one else was doing what we were doing when the UK’s independent review into the AI industry in 2017 used our data because there wasn’t anything else.
In late 2018 our progress accelerated. I’ve been too busy to write this post since then.
We secured a contract with the Greater Manchester Combined Authority who were using EU funding to create an evidence base for their industrial strategy. We completed work in Lille that showed us what was possible and valuable beyond the UK. Methods such as Jan Kinne’s “Predicting Innovative Firms Using Web Mining and Deep Learning” were published and generated valuable discussion. Microsoft released ML.NET and updates to Visual Studio, .NET Core, and Azure that made development and deployment of machine learning services at scale much cheaper and easier.
We raised money in a funding round to hire more people and make the investments that we needed to meet our commitments. We enjoyed early support from KPMG and others, both as paying customers and as super users of our early alpha products. It’s been hard but we’ve done well.
I still haven’t told you what The Data City does. I never have on this site.
That’s because when you’re developing a new product that requires a million pounds of expertise, money and time to create you get scared about telling people too much before it’s ready. Especially when you know that your competitors and some of your clients are spending much more money trying and failing to copy you.
So what does The Data City do?
What do companies do?
The Data City creates new SIC codes, in a new way, for new industries.
That sentence needs some explaining. Let’s start with SIC codes.
Standard Industrial Classification (SIC) codes were created in 1937 to standardise how different parts of the US government classified businesses. Something similar has since been adopted in almost every country in the world.
These systems assign a code to every company in the economy. In the UK a deep coal mine is 05101. A manufacturer of assembled parquet floors is 16220. Processors of seed for propagation are coded as 01640.
These codes work well for agricultural and industrial sectors. Precise definitions for a wide range of industries go into very small niches. But as employment in these sectors has shrunk (industry and agriculture combined make up less than 20% of the UK’s economy today) and as new sectors have grown and become less precisely defined these niches tell us less and less about our economy.
Three SIC codes — Manufacture of cutlery (25710), Manufacture of watches and clocks (26520), and Cold rolling of narrow strip (24320) — together employ fewer than 1000 people in the UK.
Three other SIC codes — Management consultancy activities other than financial management (70229), Information technology consultancy activities (62020), and Other business support service activities n.e.c. (82990) — employ well over a million people.
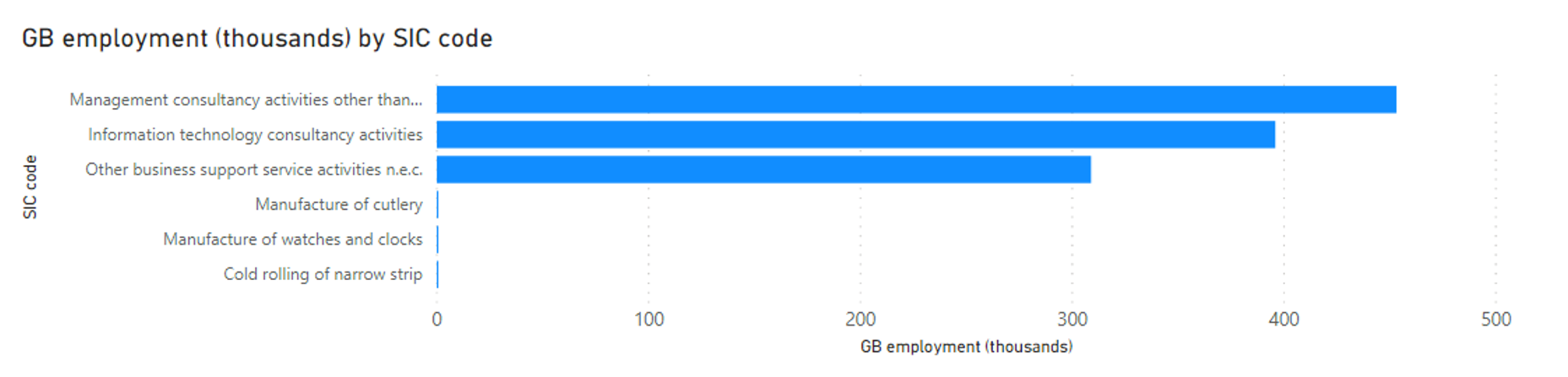
Today, the system that we use to classify the sectors of our economy has huge complexity and nuance in some areas that employ almost no-one. And it has almost no precision in areas employing thousands of times more people.
When most people hear about this problem their temptation is to fix it by adding more complexity and nuance to the existing system. Many efforts have been made to do this. None has succeeded.
Here’s one big problem. Manufacture of cutlery is persistently and obviously different to the cold rolling of narrow strip. The same cannot be said within most broad service industry definitions or within many emerging areas of manufacturing.
Among the 400,000 people working in the UK in SIC code 62020 (information technology consultancy activities) there is agreement that different companies do different things, but there is no shared, exclusive, and persistent definition. One company may specialise in the sale and maintenance of databases to large businesses, another may focus on the sale and maintenance of websites to small businesses, another may manufacturer devices and write software that speeds up existing databases of both types within companies. They may all have picked the same SIC code for themselves when they last updated it, and within each company almost every employee would define what their company does very differently.
It was easy to say what Nokia did when they manufactured rubber boots. Today it is much harder.
To fix this we think about SIC codes differently. To show that difference we call them RTIC codes, Real-time Industry Classifications. Four big differences between RTICs and SICs are,
- We don’t limit the number of RTIC codes that a company can have.
- We use a company’s whole web presence to assign it RTIC codes instead of asking it to self-identify from a set list.
- We create new RTIC codes constantly to reflect new niches of activity.
- We update our assignments continually.
The only way to get a feel for how our process works and what value RTICs offer is to work through an example.
RTICs and The Data City process for creating them
Here’s how our process works. This is one of the simplest examples possible and takes about an hour. The hour is split into 15 minutes of work and 45 minutes of processing time. The creation of the far more robust RTIC codes that we publish for wider use typically takes a week.
The Data City creates lists of companies. In this case we will create a list of soft drinks companies. I start by selecting a company that I know operates in this sector, I’ve chosen Britvic and added it to my list.
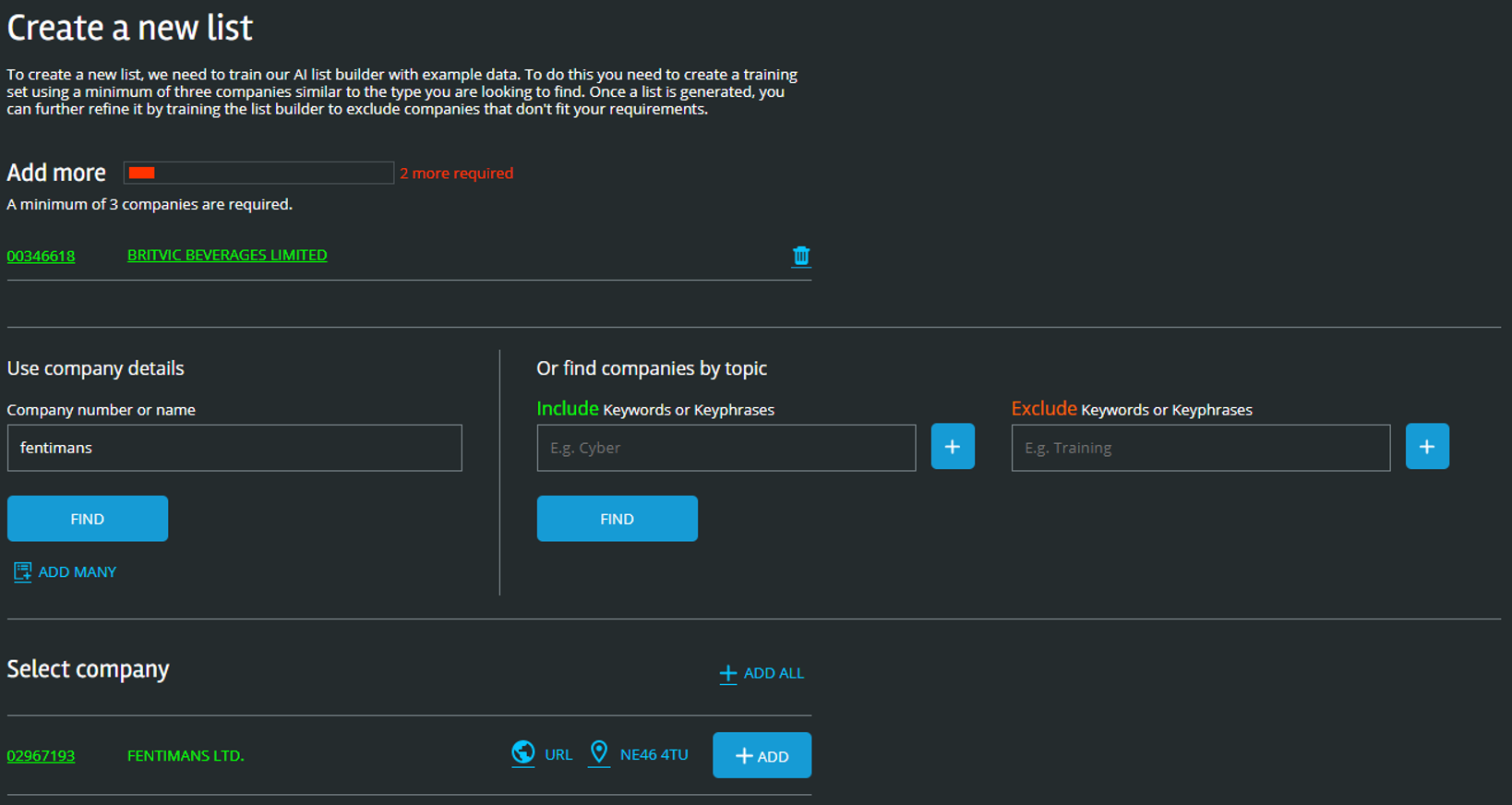
I’m prompted to pick at least three companies, so I added Fentiman’s and Innocent and started building my list.
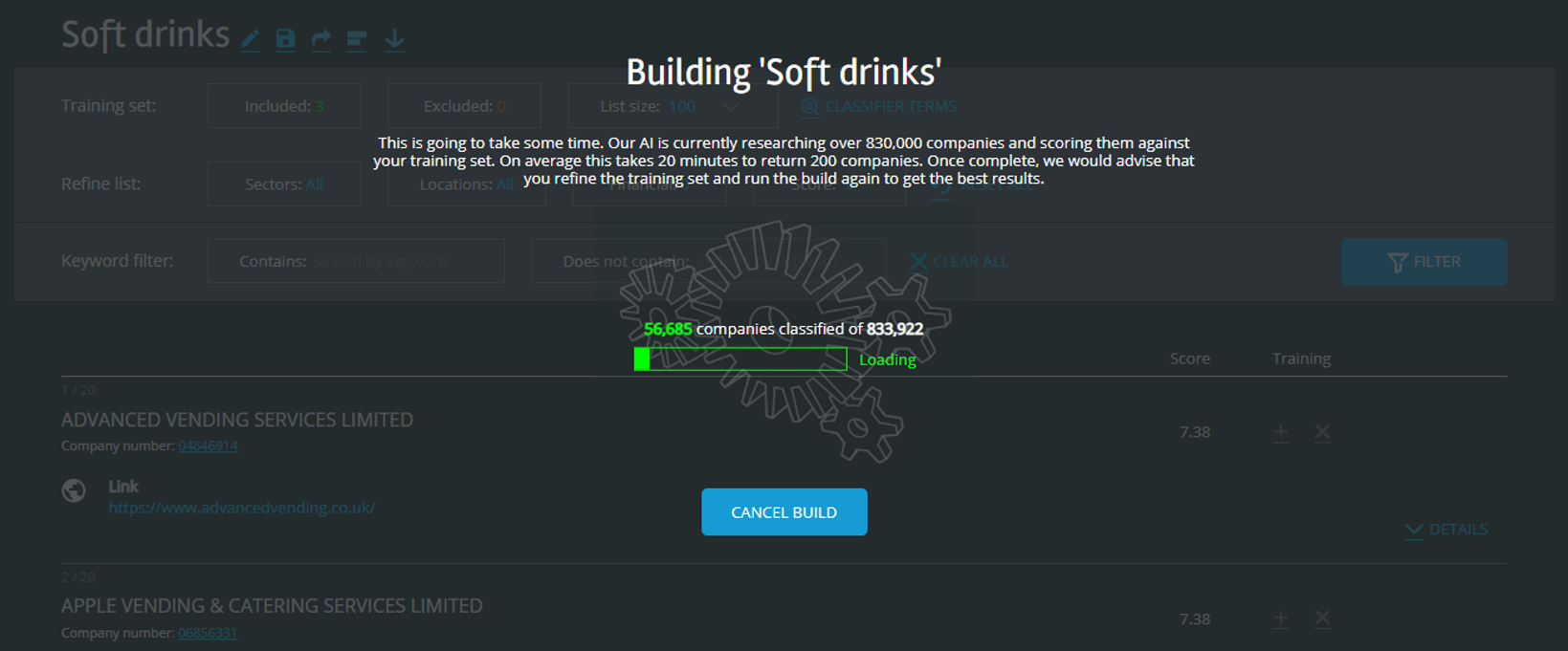
After 15 minutes I have ranked nearly one million UK companies by the similarity of their web presence (this is a simplification, but a pretty good one) to the web presence of those three companies.
The result is not very good. Companies called Innocent Music Limited and The Innocent Pet Care Company have similar web presences to Innocent Limited (who make soft drinks). I bet they all use the word “innocent” a lot. We teach the machine learning algorithm that this similarity is unimportant by clicking the red cross and adding these companies to the exclude list.
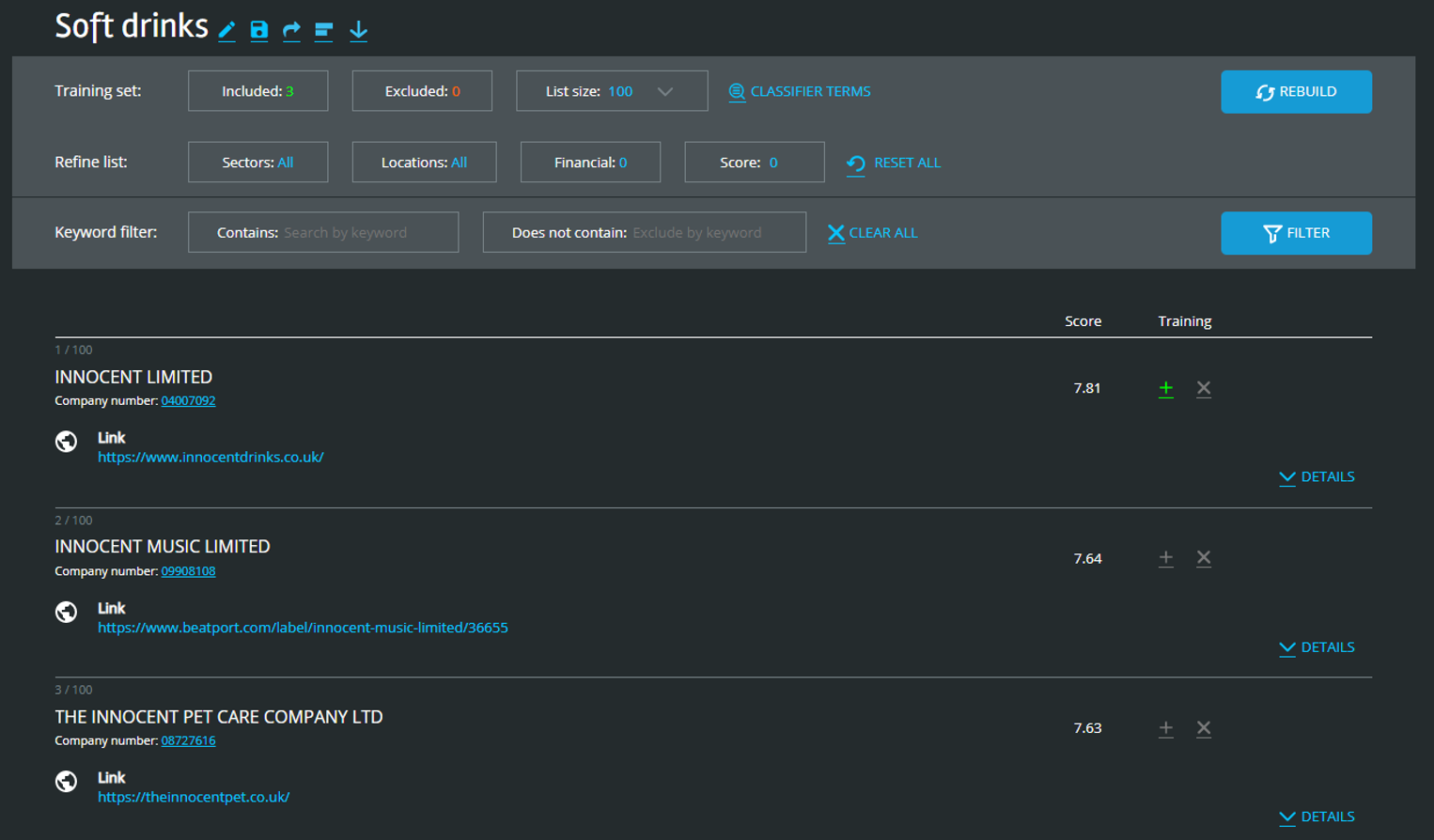
Other matches that we don’t want in our final list are London Pilsner (not a soft drink company) and Brupac (a drink dispensing company).
Companies in our first list that we want to add to our training set as positives are Merrydown PLC and Clearly Drinks Brands Limited.
So far our process has taken 25 minutes, of which 15 minutes was drinking a mug of tea and answering some emails while the machine learning classified a million companies for us. Already we can see the power of this approach. We have identified two companies that definitely work with soft drinks that are not on the British Soft Drinks association membership directory.
But we’ve only just started. With our improved training set we press the rebuild button and wait another 15 minutes.
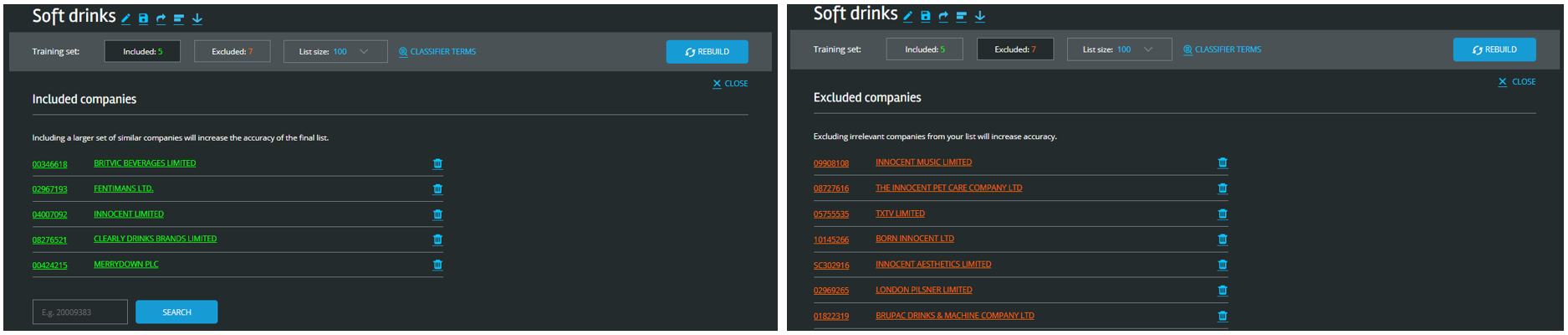
Another round of improvements and we’re done. We now have a list of 100 UK companies working with soft drinks.
With this amount of work we’d expect about 1 in 5 to be false positives. It doesn’t take much more work to get that down to 1 in 20.
For each company we have the last three years of their finances, the number of people they employ, their operating addresses, the URL of their websites and those website’s contents, their directors, their social media accounts, and much more.
Now we click the insights button.
Instant insights
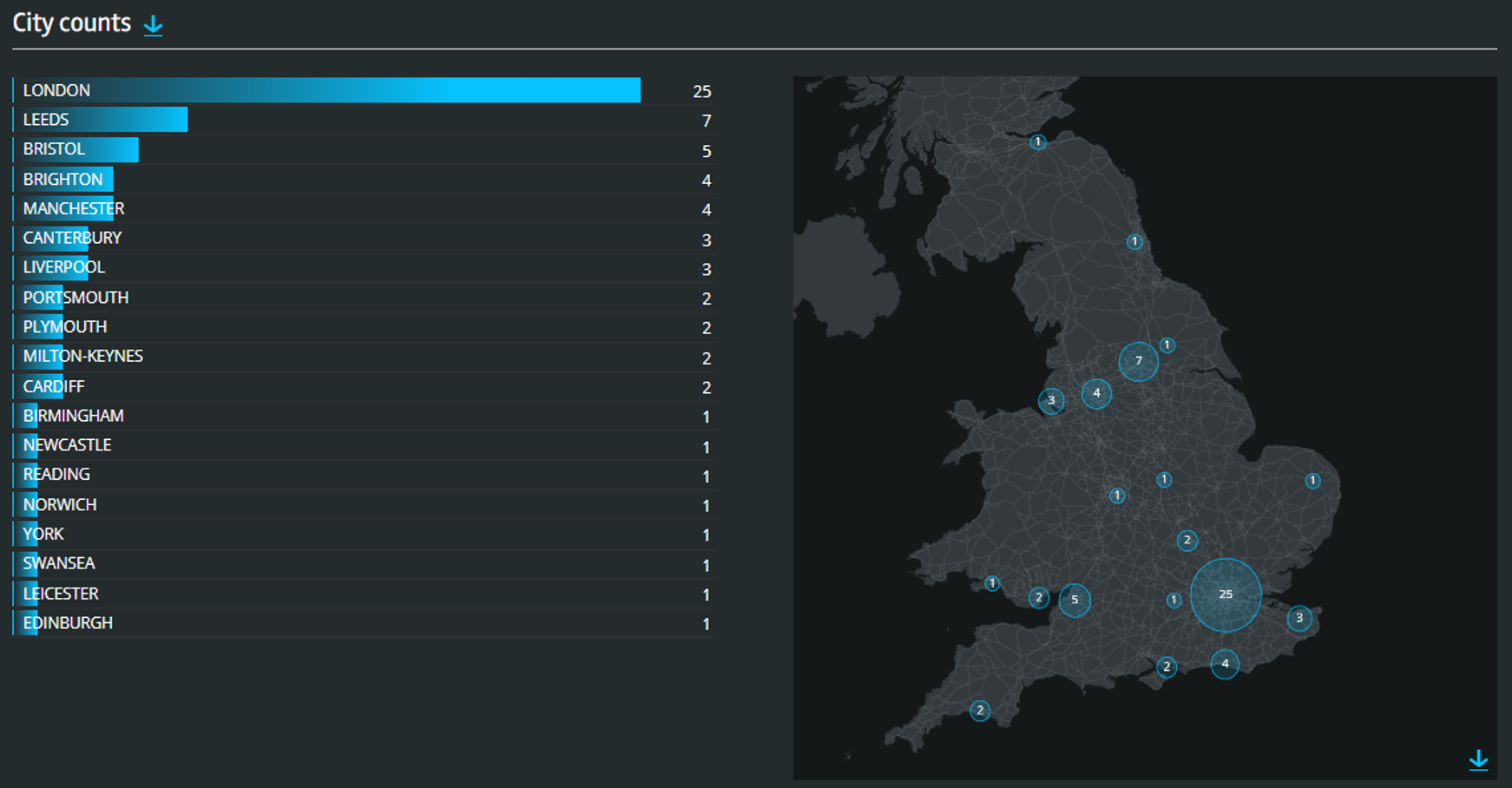
The insights section of our tool instantly summarises the properties of all the companies in any list. So we can see which cities (functional economic areas, local authorities, combined authorities, etc…) our companies are based in, and see that on a map.
We can also see what SIC codes the companies on our list have.
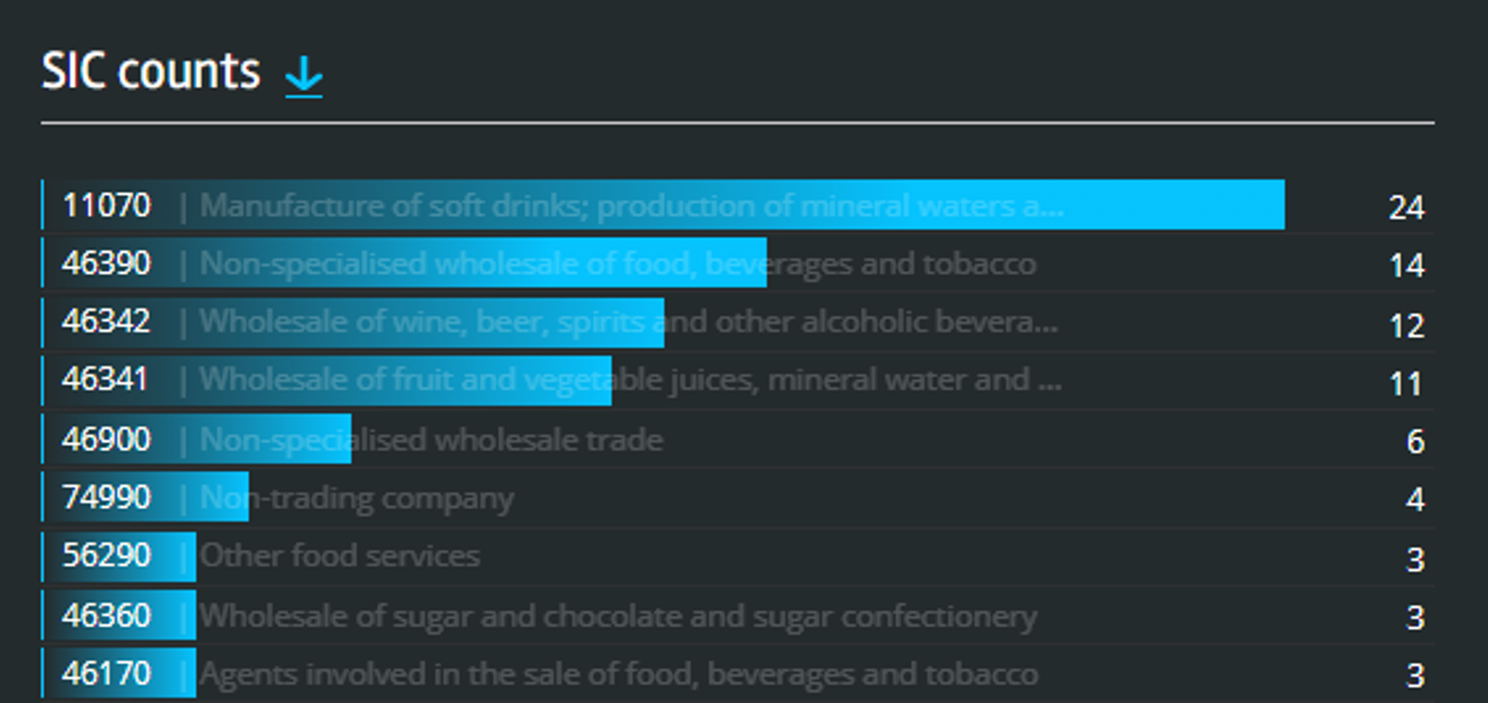
This gives us a sense of just how different our approach is to traditional classification. Even with an example this simple, focusing on an area so well-defined in the existing SIC system, we return companies in over a dozen SIC codes.
There are lots more analysis features in the insight tool. Things like the growth of the sector in terms of employment and revenue, the gender pay gap in the sector, and the overlap with other sectors.
And if that’s not enough, there’s the ability to download the raw data for analysis in your own toolsets. We use PowerBI a lot nowadays.
As I wrote at the start of this blog post, this a simple example, my explanations are simplified, and I’m sharing just what’s needed to tell the story. The last oversimplification I want to share is an explanation of how our AI works.
Explainable AI
First of all, our “AI” is mainly linear regression. There’s some clever tokenisation, some reasonably smart weightings, a few extra bits that make things work much faster than they should, and a few secrets that I’m very proud of the team for developing. No I’m not sharing them here.
But it’s mainly linear regression.
And since it’s linear regression we can explain how the main part of our process works. In fact we make it part of the UI of the tool. This is the explanation of how our process decides whether a company is part of the Soft Drinks list we’ve just created.
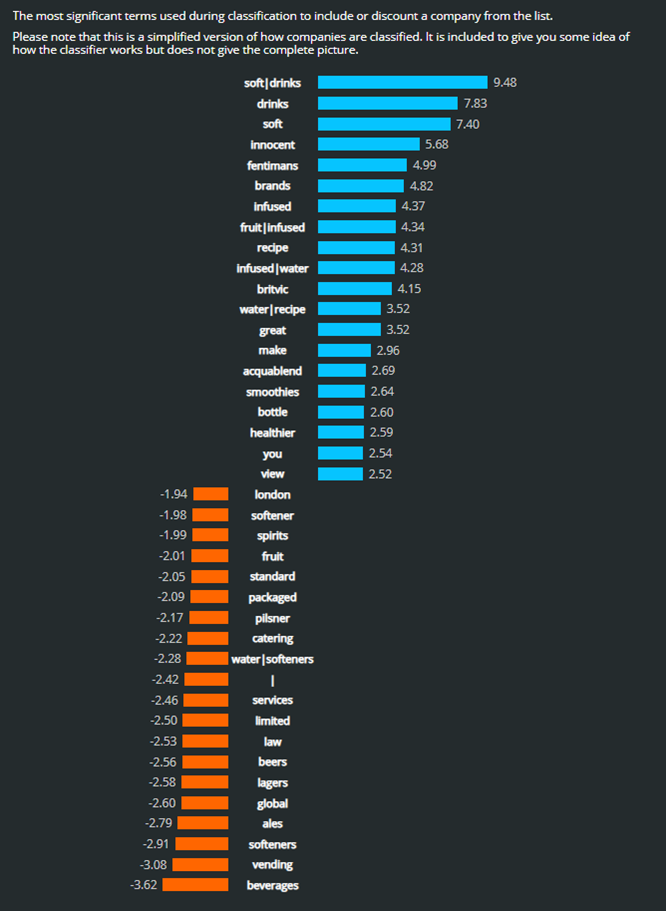
Some of the results here are obvious. The surest way to guess that a company is involved in the soft drink industry is if its web presence contains the word soft drinks. But many of the results are not. If a company’s website mentions beverages that’s (surprisingly) a sign that they don’t work with soft drinks. The word is strongly linked to alcoholic drinks.
This view of our AI is a simplification of what’s really happening. There are more parameters that determine whether a company is a member of our list than what we can show here. But it’s a decent approximation of what’s happening. It usefully highlights problems with lists as they are being built.
In this example we see that the word London existing in a company web presence is considered a weak sign that it does not work in soft drinks. This seems unlikely, and indeed 25 companies in London make it onto our list despite this (it’s just a weak sign after all). The word is probably there because we added London Pilsner Limited to the excluded part of our training set. For similar but opposite reason the words innocent, fentimans, and Britvic are in the positive side of our algorithm explanation.
This is a simple list. I built it in one hour. I’ve mentioned this already. And the presence of London, innocent, fentimans, and Britvic in the scoring algorithm that decides whether a company is classified as being in the soft drinks sector shows that one hour isn’t long enough to build a great list.
As we add more companies to the training set, those words will disappear. Another twenty minutes of work should be long enough to get there with this list, and we’ll know when we’ve done enough work because of the way that the AI’s decisions are explained. Do that and you’re getting towards creating an RTIC code.
In a national AI debate in the UK which talks about explainability a lot, I find this a nice example of why most companies working with AI are also working on explainability. It makes our products better and that’s worth investing a lot of time in, even if the most useful ways of presenting the explanations don't completely describe how the decisions were taken.
Which brings me onto the last topic of this blog post. Actually existing.
It actually exists
Ben Goldacre and his team’s work on OpenSAFELY is a truly world-leading achievement in a sea of bullshit claims that Britain is leading the world at everything. Or in his words, “the key thing about OpenSAFELY, in a world of data science promisers, is that it actually exists.”
And it’s the same with what we’ve built at The Data City.
For a decade I’ve listened to economists and consultants and academics say that SIC codes were already nearly useless and becoming worse every year. I’ve also heard most of them say that all alternatives and all possible alternatives were so flawed that they weren’t worth creating. I’ve been told lots of times in recent years that what I’ve just shown would never work. And of course as soon as it worked I was told by the same people what what we’ve built is overly simple and much better versions already exist. Years later in many cases I still haven’t seen those tools. The Data City actually exists.
That it exists is thanks to lots of people, businesses, and institutions. I’ve already mentioned some and if I mention more it increases the risk that I’ll leave important people and organisations out. So I’ll keep that for another blog post.
What I want to finish this post with is what I think other companies, governments, and institutions should now be doing with this tool.
So what? What’s next?
Most of my class from university worked in financial services after graduation. I was determined not to. So it is a bit annoying that after fifteen years I have stumbled into working in financial services.
But our lists are extremely good at identifying companies that private equity firms want to invest in, that large firms want to acquire, and that business consultants and accountants want to help grow. So now I work in financial services (though only according to our RTIC codes; our SIC code is, of course, almost useless).
But there is another area where this technology works brilliantly: industrial strategy.
If the UK is serious about using data in government, and if it’s serious about levelling up, and if it’s serious about industrial strategy, then it needs something like our data and our tools. Currently, for all their claims and assurances, too many of the UK’s major national institutions and too many government departments don’t know very much about what our economy is good at and where those strengths are. Too often they lack any reasonably objective way to tell the hundreds of places that ask for huge investment every time there is a competitive funding round that they are actually not good at what they claim to be. They lack knowledge about where clusters of excellence exist and what sectors they are in.
Through a combination of proximity and a drive to innovate and support economic growth, some of the UK’s large cities already understand their economic strengths well. But within such a centralised country there isn’t much that they can do with that knowledge. It is not in their power.
If the UK is serious about using data in government, and if it’s serious about levelling up, and if it’s serious about industrial strategy, then it needs something like our data and our tools. I’ll probably focus on selling them that for the rest of the year.