
Measuring tech in the UK and France in 10 steps.
I recently worked on a big project where my small role was to search for cities in the UK and France that are leading in data industries. I can't share the work yet, so please don't ask.
First thing first. Paris and London win. They’re much bigger than other cities in France and the UK. They’re centres of government, research, and business on a scale that other cities aren’t. They are unique within their own nations. Plus they really mess up graphs when you include them; everywhere else gets squished into the bottom-left corner and you can’t see anything.
So I won’t mention Paris and London any more. I’m searching among the other cities.
Here’s what I did.
1. Figure out that the data exists.
I know that a list of UK companies is open data and easy to find. And I know that with more time and money than I had for this project you can get estimates of turnover and employee count by business type. Nesta have done it for the creative industries and described their methods, so it must be possible.
But when I started this project I didn’t know if the same data existed in France.
Now I know that it does. It’s called Sirene. It contains some useful details about the size of each company that we don’t get in the UK dataset and this lets us ask a better question later on in our analysis. Look out for that.
2. Download the data.
So I went and downloaded a list of every company in the UK and in France.
In the UK that was five zip files ( I complained , and now you can download the data as a single zip file) totalling 330MB. In France it was a single zip file of 1.4GB .
Just a few minutes later I had data that was almost impossible to get hold of outside of government just a few years ago. Open data is great!
3. Get rid of lots of data.
The first thing I did was get rid of a lot of data. When you expand the Sirene database zip file it’s 10.6 million rows. That’s over 8GB of text.
That won’t open in something like Excel. Even in a heavy-duty text editor like EmEditor it’s a challenge.
So to make processing easier I deleted every line that didn’t contain any of the NAF codes (they’re the same as SIC codes in the UK) of interest. I got rid of every company that wasn’t registered in a technology-related field.
Less than a minute later 10.6 million rows of data is 160 thousand rows.
I used findstr in Windows, you can see the command in the screenshot above. You can probably use Grep on Mac and Linux to do the same thing.
4. Play with data. Get more data. Play more.
So now I have a list of every data-related company in the UK and France. I tend to play with data in Excel and Access, but I could equally use R or some SQL database plus C#. You might prefer to use Python or Stata or SPSS or Tableau or PowerBI or Kibana.
We’re all doing the same thing. We’re playing with the data, getting more data and linking it together, figuring out the questions that we want to ask and that the data will let us ask, and then picking the best questions to ask.
Some of the extra data that I found and linked with the list of companies was the population of départments in France and a list with details about each local authority in the UK. I also used a list of which postcodes fit into which local authorities and which local authorities fit into which primary urban areas in the UK. UK geography is hard.
Most of this process of playing with data involves thinking of a question, making sure you have all the data to answer it, and then asking it in a precise way. We call these precise questions queries.
Here’s an example of linking data to ask and answer the question “list the départements of France, ordered by the number of people working in data-related companies, and give me the population of that département”.
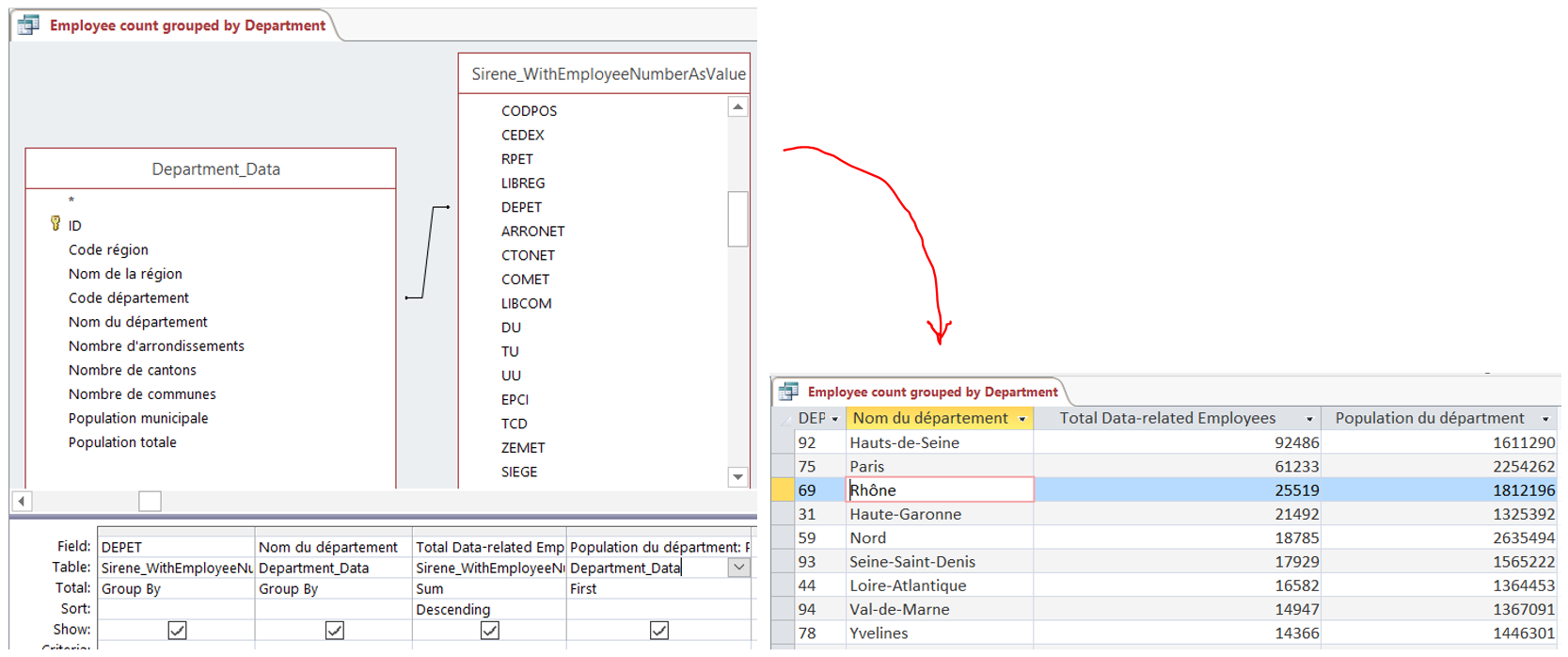
I did some more complicated queries too. Ones like “show me every data-related company in each French département but only show me those companies with over 200 employees if they’re a national or multi-national company or those companies with over 20 employees if they’re a local company. And show me both the population of the département and the name of the largest city in the département too”.
I like using Access to write those types of queries because I find that I make fewer mistakes if I use the UI to help me. I can write them in SQL (standard query language) directly if I need to. Access helps with that too.
Often, later on, I’ll rewrite my final queries in MySQL + PHP or SQLite + C# to make them quicker and easier to repeat in the future. It also helps other people who might not have Access copy my methods.
5. Pick some outputs and create them.
Once I’ve figured out the questions that I want to ask, I tend to write them down on paper and go back to the start. That means downloading the data again, populating my databases again, linking the data again, and writing the queries again.
That sounds like a waste of time, and I often cheat a bit when I do it, but I think that this is important.
While I’m playing with data I often make changes to it. Sometimes these end up giving me beautiful results that aren’t true any more. That’s very embarrassing. So I start again to avoid fooling myself like this. And when you already know what questions you’re going to ask, and how you can ask them, you’ve already done most of the work. Starting from nothing isn’t much extra work.
After finding, linking, and playing with the data for a few days I ended up two questions that I could answer.
1. In France, which cities with more than 5000 people working in data-related jobs have a notably high concentration of people working in those jobs.
2. In the UK, which cities with more than 2000 data-related businesses have a notably high concentration of those businesses.
The two graphs below give the answers.
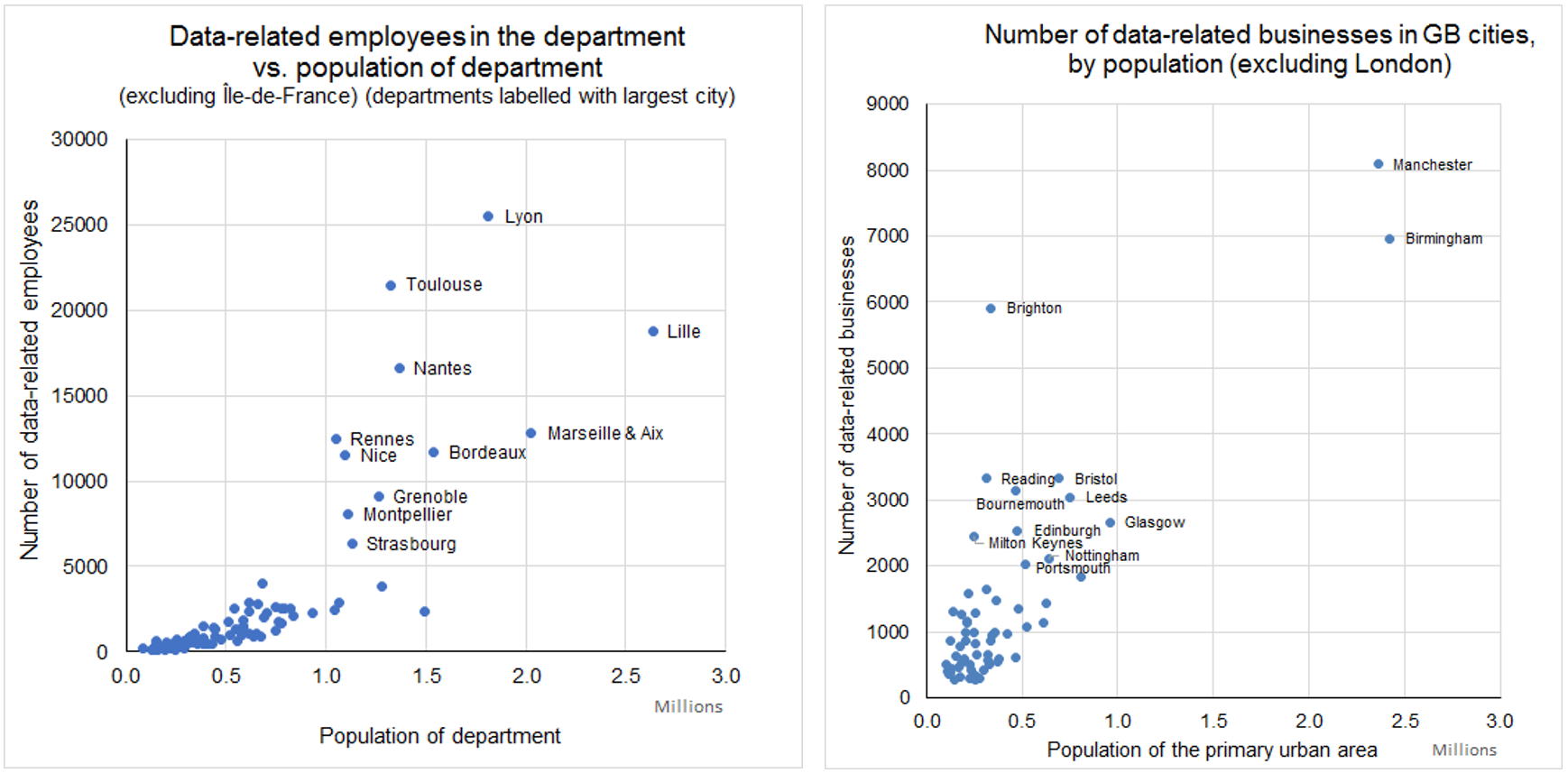
Lyon, Toulouse, and Rennes are the answers for France. Nice and Nantes do well too.
In the UK, Manchester beats Birmingham among large cities. Bristol beats Leeds and Glasgow among medium-sized cities. Brighton beats everywhere else when it comes to small cities. So those are my three choices.
Paris and London are way off to the top-right to the graphs. I already explained why I’m ignoring them.
For each French city I compiled a list of companies, ordered by size. Below you’re looking at big companies in Lyon that might be doing things with data.
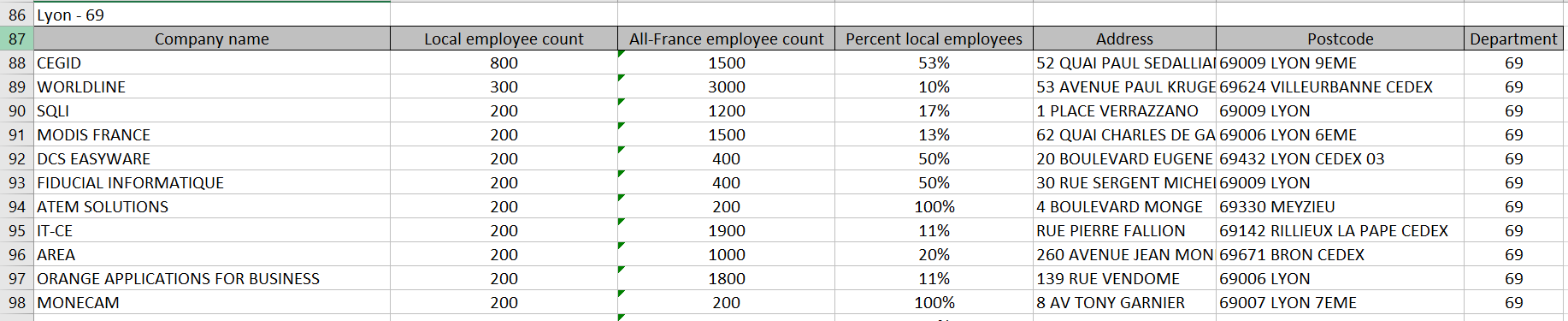
And here we are a bit further down the table looking at small companies in Lyon that might be doing things with data.

Because the UK list of companies dataset doesn’t include company size we can’t do this easily. So instead we used recent TechNation reports as a starting point to identify key companies in each city of interest.
6. Do lots of manual work and submit my report.
So now I’ve done my data bit, but there’s a huge amount more work that goes into a report. I added Universities and government bodies. Then picked out a few of the top companies from each list to check if they’re really doing anything with data. Then did lots more small things that we can talk about if you’re really interested.
Just like when I was playing with data to find the questions I wanted to ask, a lot of this work never made it through to the final product. That’s normal and healthy.
Lots of other people also worked on the report. They interviewed people in France and the UK, checked the results that I’d found, and much more.
And now I’m writing this blog, and if you’re like me you’re probably asking yourself why
7. Write this blog.
Writing things up and publishing it in a blog takes time and I don’t get paid for it. I do it for a few reasons.
I want to document my work so that I can find it, repeat it, and build on it in the future. I’ve kept a notebook ever since I trained as a scientist, but it’s messy and hard to search. Writing up projects like this makes things easier to find. I wish I’d blogged as a scientist.
I also want to let people know what I’ve done. This work took me nearly two weeks of long days. Now that I know what I need to do I could repeat it in a few days. It took a lot of failures, wrong steps, and corrections. A lot of work got thrown away. So I hope that by sharing what I’ve done I might help others in the same way as reading other people’s blogs helps me to do things.
I also hope that people who see my work might want to pay me to do something similar for them.
There’s a downside to sharing too. Other people could copy my work. But I think that this usually leads to more work for me, not less.
The biggest negative to sharing by far is the trolling. There’s almost always some people who say that they could have done the same work in an hour and who tell me that I’m an idiot. Most of the time they’re wrong, but sometimes they’re not.
One of the most difficult and definitely the most important thing that I do at work is to decide which criticisms and suggestions are worth pursuing and which are a waste of time. I have no idea whether I’m wasting too much time or dismissing too much criticism. I worry about this a bit, but I have friends whose productivity is really affected by this. It’s especially hard for women in tech. They get much more trolling, which means that they have to make more choices between pursuing criticism and dismissing time-wasters.
8. Play around with things that I could have done and might try next time.
To keep earning money I need to continually learn new things. So at the end of a lot of projects I go back and try something new. Once you know what answer to expect you can check if new methods are good much more easily.
So I tried to load the full Sirene database file into PowerBI. Microsoft says that it can handle big data. It can’t. I gave up after 20 minutes. The 180MB version of the Sirene file that I created earlier loaded fine.
I did some cool stuff with it in about half an hour. I could plot in which month and in which year every company was founded. I could put companies on a map (though there were too many for it to work). It was interesting.
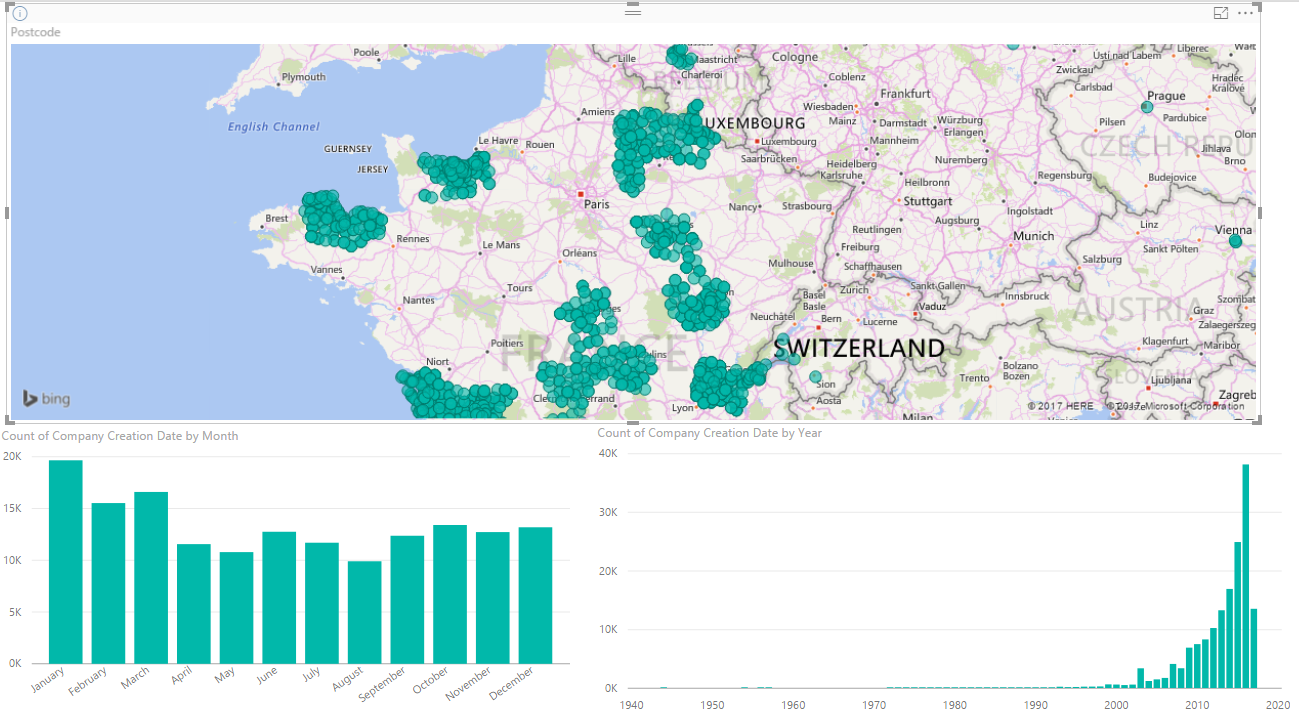
I think that I could probably have got a lot of the output I eventually produced for the report from this tool. There are other tools like Tableau and ElasticSearch/Kibana that do similar things. There’s a good chance that over time they’ll take over more and more analysis and presentation from the old-fashioned tools I use. I saw the same happen with Google Analytics when it took over a lot of web traffic analysis and it was generally a good thing.
But for now I think that I still need to know exactly what I’m doing with my data instead of just throwing it up on interactive panels.
9. Oh wow you’re still reading.
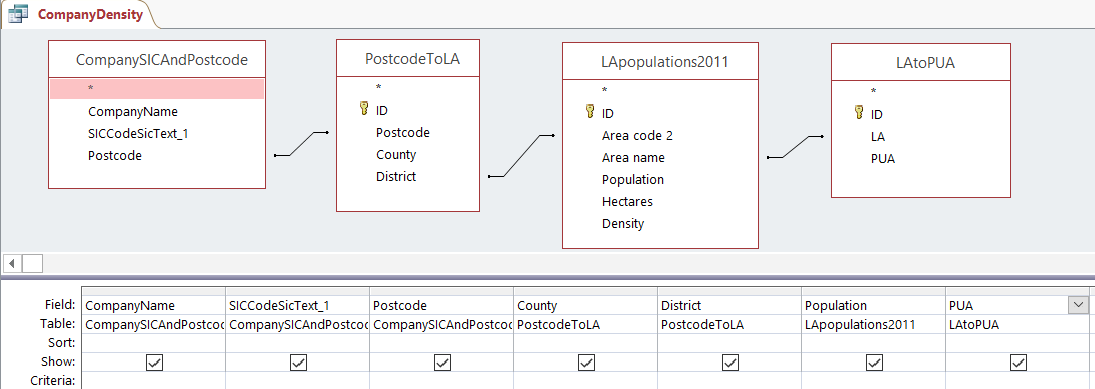
The biggest query I wrote was “list every UK data-related company, lookup the local authority they’re in by their postcode, then lookup the population of that local authority – oh and tell me what primary urban area that local authority is in too”. It’s above as a picture.
10. I admit it: SIC codes (and NAF codes) aren’t great.
Last but not least, I want to admit to a problem in my work. This should be a good thing to do, but I’ve found it very risky. People who are looking for an excuse to say that my work is crap love what they see as an admission of that. You’ll see this in academic publishing a lot too. But I’m pretty confident that these people won’t have made it to word 2000 in this blog so I’ll be honest.
SIC codes are not a great way to categorise companies. What is a “data-related company” anyway?
Every company uses data. Asda are a food company right? But their logistics process, shared with their parent Walmart, is a hugely advanced data-driven system. And yet they don’t show up in my work.
People are starting to move behind SIC codes using web scraping. Data City do it in their IoTUK Nation work . There’s a great explanation of how industry classification by web scraping works right here .
I don’t think that this makes my work bad. It just means that soon we’ll be able to make it even better.